网络问答
标题:
【小白教学】如何用YOLOv7训练自己的数据集
[打印本页]
作者:
赵嘉悦
时间:
2022-11-25 16:54
标题:
【小白教学】如何用YOLOv7训练自己的数据集
一、设备准备
我用的是V100*2,总共64GB显卡内存,在Ubuntu 18.04系统,python 3.7.10下运行。
二、代码克隆,环境安装与权重下载
1. 代码克隆
代码的克隆和环境的安装在官网上也有指导,可以直接跳转到官网查看。下面是具体的操作,跟官网的一样。首先,直接把项目从官网上克隆下来,在终端输入如下命令
git clone https://github.com/WongKinYiu/yolov7
代码克隆过程
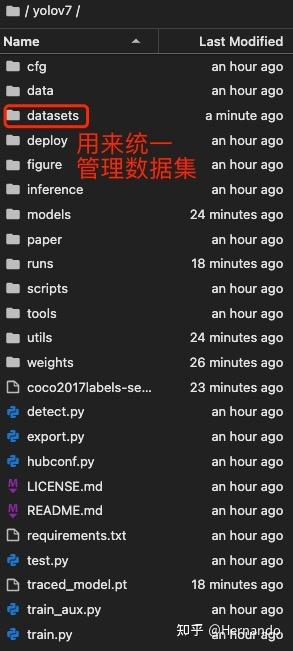
代码的克隆过程看服务器的网速,有的需要两三分钟,有的几十秒即可。克隆好了之后,打开yolov7,可以看到如下的文件。
2. 环境安装
然后进入到项目文件夹中,进行环境的安装,分别输入一下两行代码即可。同样地,速度受服务器网速影响,但是都不会太久。
cd yolov7
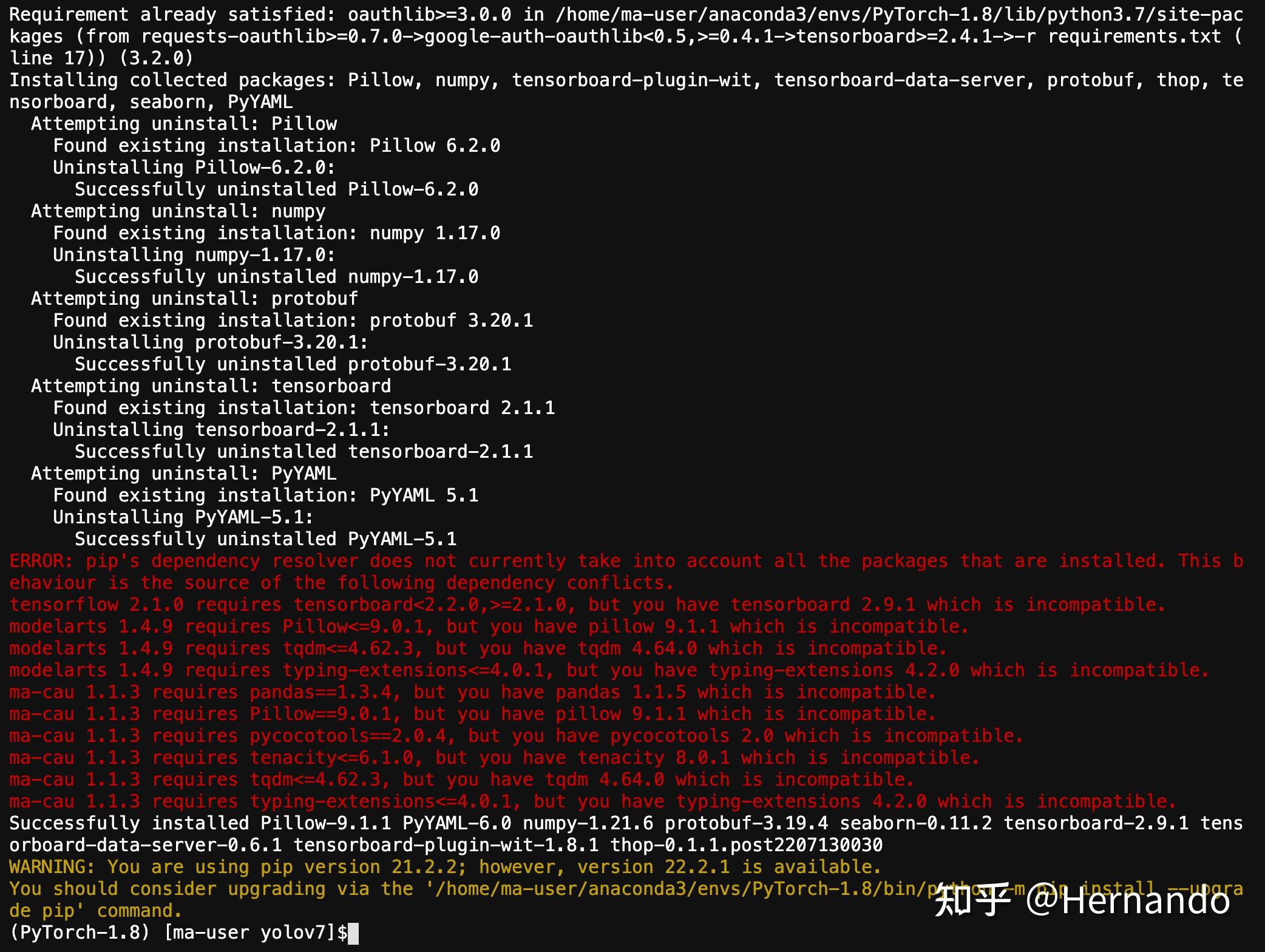
pip install -r requirements.txt下面是环境安装好之后的结果截图。
环境安装好之后
3. 权重下载
这次我们使用的预训练模型是yolov7_training.pt,这个模型是在MS COCO数据集上进行训练的,我们把这个模型下载到/yolov7/weights/下。注意,我们需要创建一个/weights/文件夹,用来统一存放我们的预训练模型。输入如下命令进行文件夹的创建,并进入到该文件夹下
mkdir weights # 创建文件夹
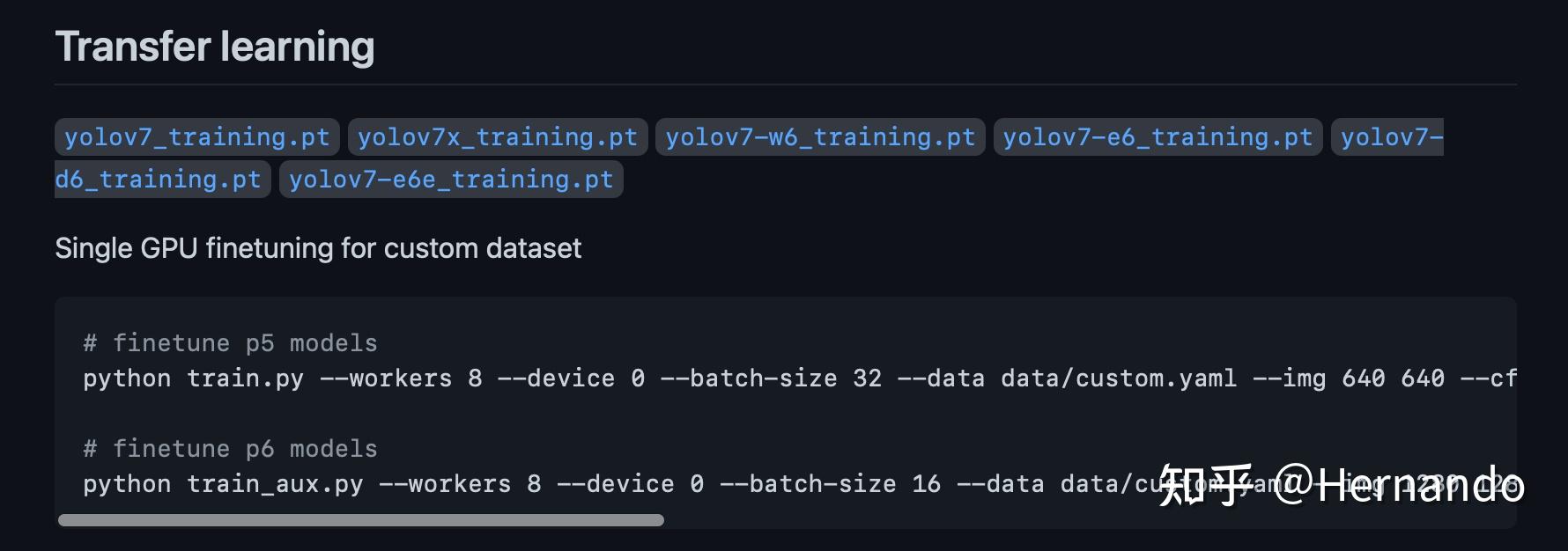
cd weights # 进入到该文件夹下这些预训练的模型官网都有提供,掌握如何训练自己的数据集后可根据需求进行预训练模型的更改。官网的截图如下:
官网提供的预训练模型
在终端输入如下命令,即可下载预训练模型
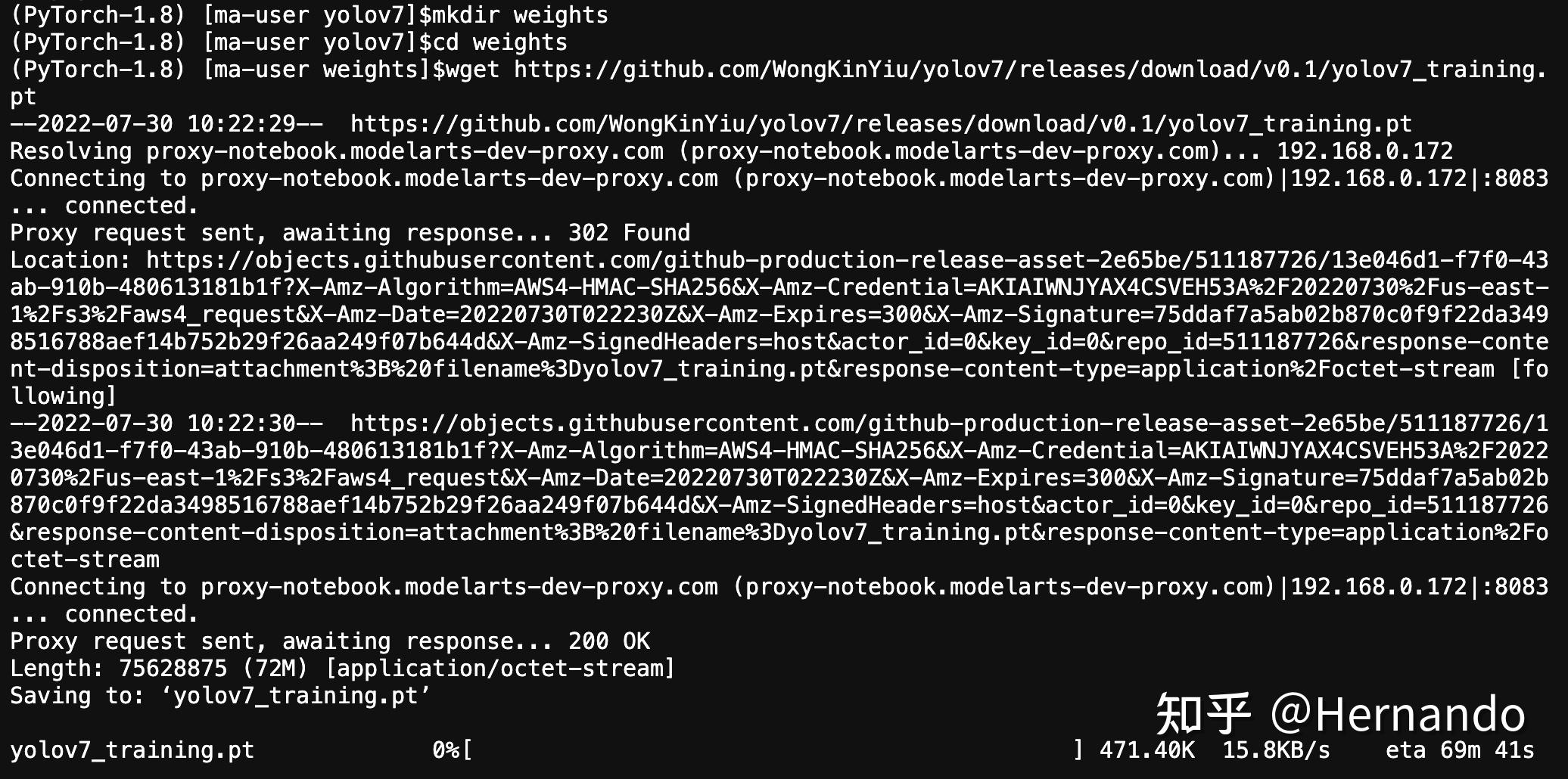
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt下图是下载过程的截图,同样是受服务器的网速影响。可以看到,我只有十几KB/s,而整个文件大小为75.6MB,所以这个速度是不够的。这里建议手动下载,然后手动传到服务器上,这样速度更快。
下载完后(或者上传好后,我是手动下载再上传的),会在/weights/得到一个如下图的文件
然后我们回到上一级工作路径下,也就是/yolov7/下,输入如下命令
cd .. 到这里,我们的预训练权重也就下载好了。
4. 测试一下
这一步的重要目的,是测试环境是否都安装好了,如果能够顺利跑下来并得到相应的结果,就说明环境是安装好的了;如果没安装好,则再安装一次环境即可,也就是第2步。
首先,我们下载已经训练好的权重文件(这里的权重文件和Transfer Learning的预训练文件并不是同一个文件),同样地,下载到/weights/下面。
cd weights
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
cd ..下载好了之后,得到两个权重文件。接下来,就是直接进行测试了。现在我们在/yolov7/这个工作路径下,输入如下命令
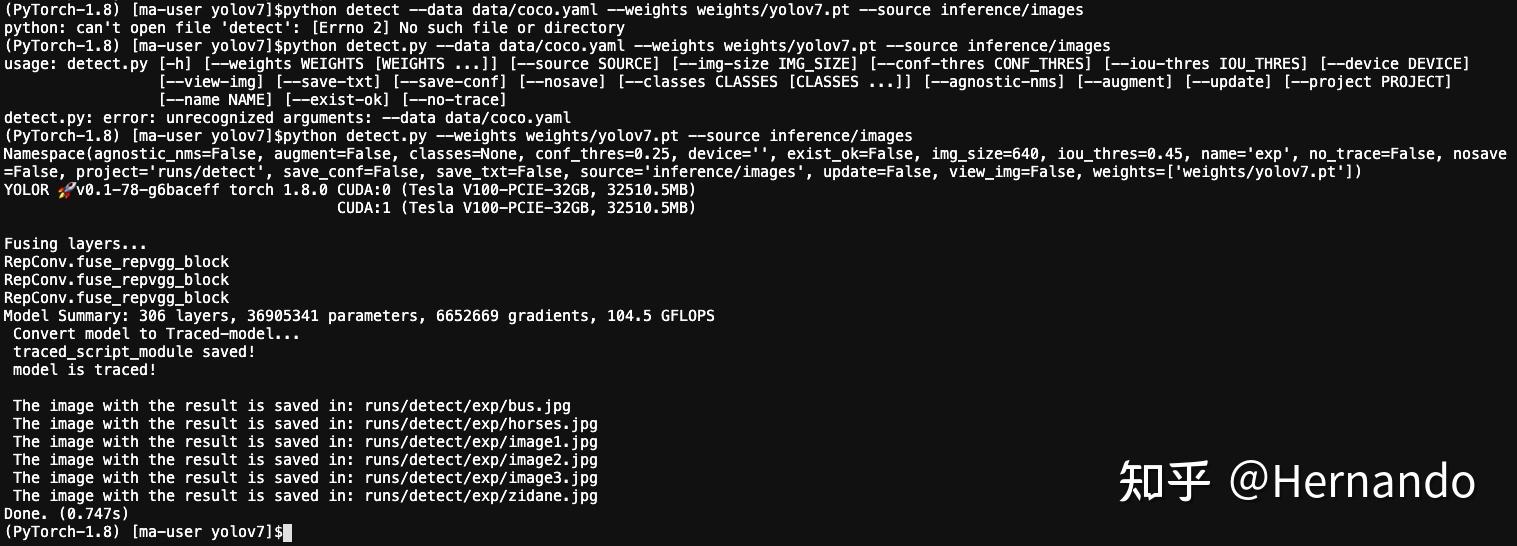
python detect.py --weights weights/yolov7.pt --source inference/images 参数说明
--weights weight/yolov7.pt # 这个参数是把已经训练好的模型路径传进去,就是刚刚下载的文件
--source inference/images # 传进去要预测的图片如果得到如下的运行结果,则说明运行成功,预测的图片被保存在了/runs/detect/exp/文件夹下
查看其中一张图片,如下
推理前,在source里
推理后
到此,就说明环境安装好了,可以进行下面的数据准备工作。
三、数据准备
1. 准备工作
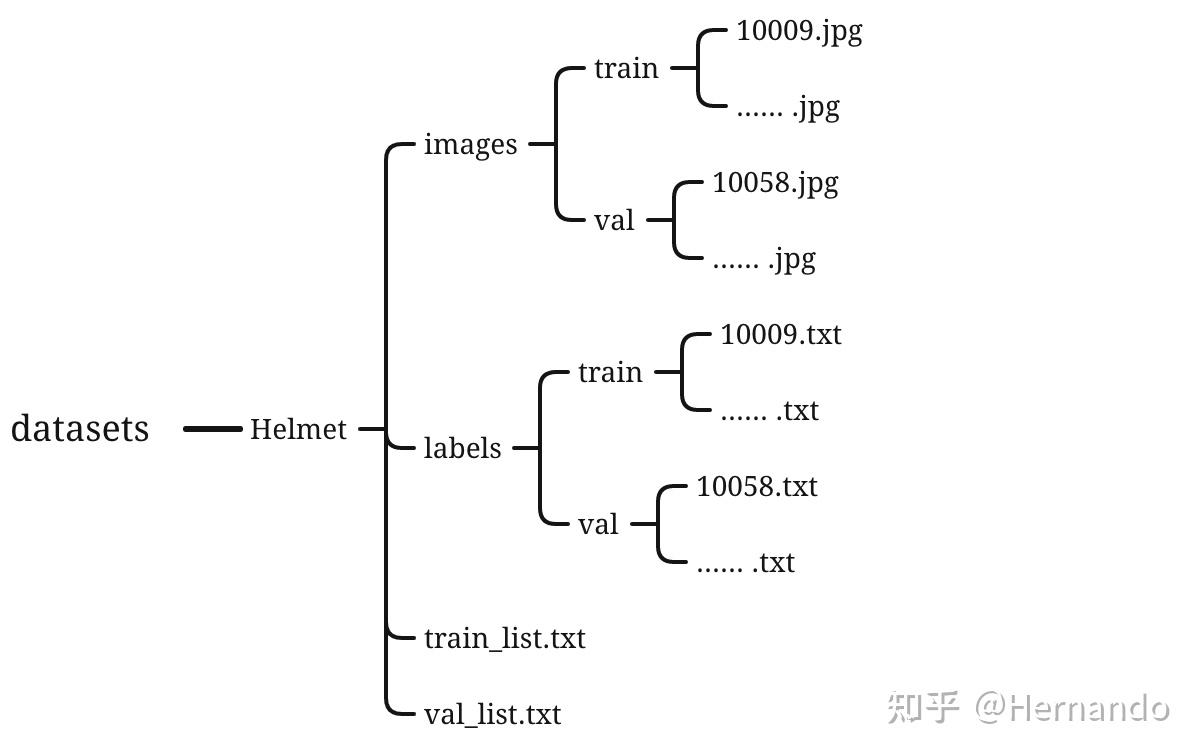
我们生成/datasets/文件夹,把数据都放进这个文件夹里进行统一管理。训练数据用的是yolo数据格式,不过多了两个.txt文件,这两个文件存放的,是每个图片的路径,后面会具体介绍。
2. 准备yolo格式的数据
2.1. 创建文件夹
mkdir datasets得到如下的结果
2.2. 准备yolo格式数据集
如果不懂yolo格式数据集是什么样子的,建议先学习一下。大部分CVer都会推荐用labelImg进行数据的标注,我也不例外,推荐大家用labelImg进行数据标注。不过这里我不再详细介绍如何使用labelImg,网上有很多的教程。同时,标注数据需要用到图形交互界面,远程服务器就不太方便了,因此建议在本地电脑上标注好后再上传到服务器上。
这里假设我们已经得到标注好的yolo格式数据集,那么这个数据集将会按照如下的格式进行存放。
不过在这里面,train_list.txt和val_list.txt是后来我们要自己生成的,而不是labelImg生成的;其他的则是labelImg生成的。
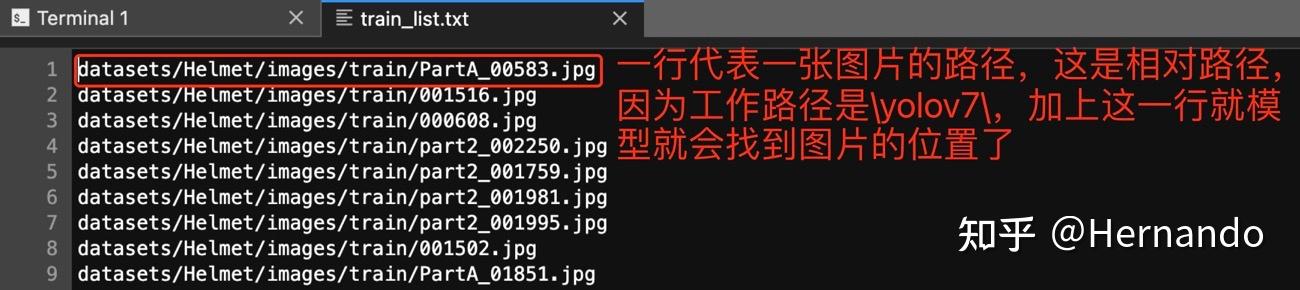
接下来,就是生成 train_list.txt和val_list.txt。train_list.txt存放了所有训练图片的路径,val_list.txt则是存放了所有验证图片的路径,如下图所示,一行代表一个图片的路径。这两个文件的生成写个循环就可以了,不算难。
train_list.txt内容示例
到此,数据集就已经准备好了。
四、配置训练的相关文件
1. 前言
总共有两个文件需要配置,一个是/yolov7/cfg/training/yolov7.yaml,这个文件是有关模型的配置文件;一个是/yolov7/data/coco.yaml,这个是数据集的配置文件。
2. 配置模型文件
第一步,复制yolov7.yaml文件到相同的路径下,然后重命名,我们重命名为yolov7-Helmet.yaml。
第二步,打开yolov7-Helmet.yaml文件,进行如下图所示的修改,这里修改的地方只有一处,就是把nc修改为我们数据集的目标总数即可。然后保存。
模型配置文件修改展示
3. 配置数据集文件
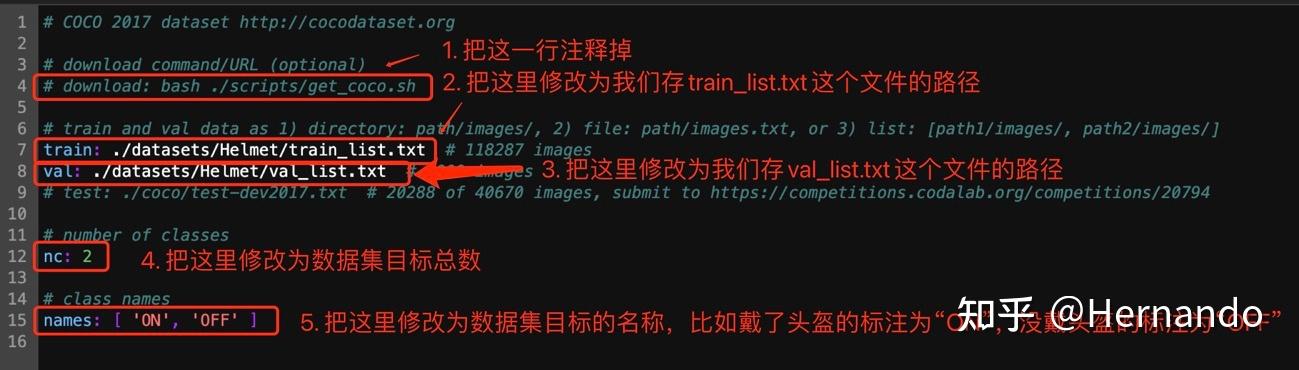
第一步,复制coco.yaml文件到相同的路径下,然后重命名,我们命名为Helmet.yaml。
第二步,打开Helmet.yaml文件,进行如下所示的修改,需要修改的地方为5处。第一处:把代码自动下载COCO数据集的命令注释掉,以防代码自动下载数据集占用内存;第二处:修改train的位置为train_list.txt的路径;第三处:修改val的位置为val_list.txt的路径;第四处:修改nc为数据集目标总数;第五处:修改names为数据集所有目标的名称。然后保存。
数据配置文件修改展示
至此,相关的文件已经配置完成。
五、开始训练
1. 前言
训练用到之前提到的三个文件:预训练模型yolov7_training.pt、yolov7-Helmet.yaml和Helmet.yaml,当然还有一些其他的超参数,具体的命令如下:
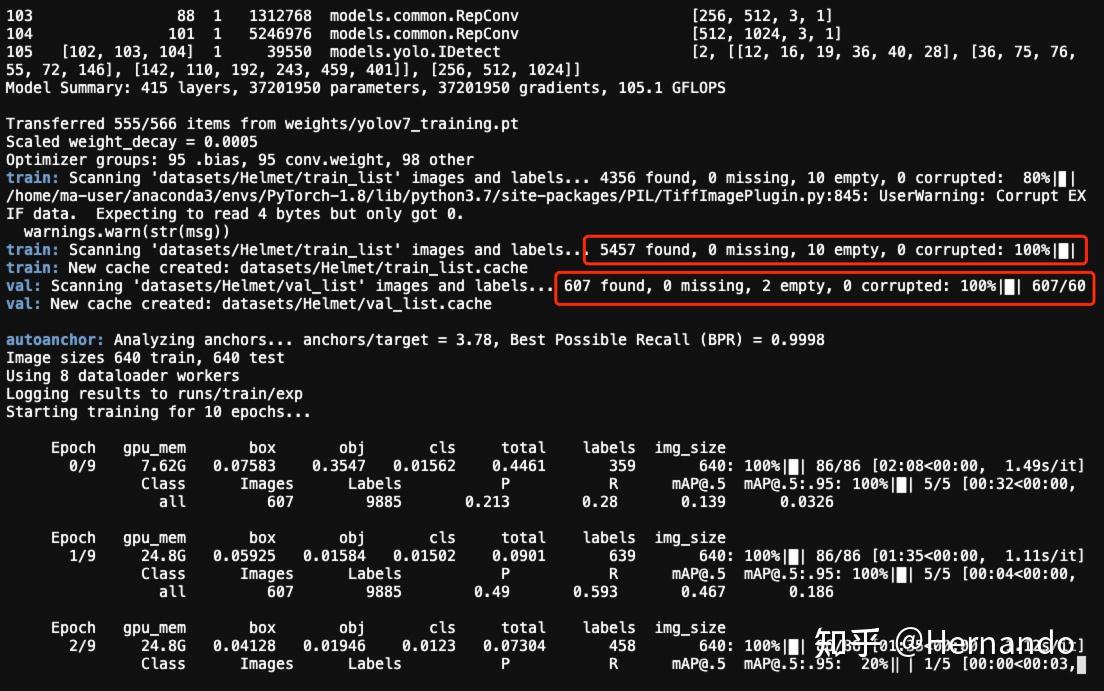
python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-Helmet.yaml --data data/Helmet.yaml --device 0,1 --batch-size 64 --epoch 10然后运行界面如下,图中红色部分表示开始扫描数据,然后会在yolov7/datasets/Helmet/下生成两个缓存文件,这两个文件是方便模型进行数据读取生成的,训练过程中不要删除。扫描完后模型会开始训练,如下图。
模型训练中
下面简单介绍一下相关的参数。
--weights weights/yolov7.pt # 接收预训练模型路径的参数
--cfg cfg/training/yolov7-Helmet.yaml # 接收模型配置文件的参数
--data data/Helmet.yaml # 接收数据配置文件的参数
--device 0,1 # GPU/CPU训练,我有2块,因此为0,1;若1块,则0;若CPU,则cpu
--batch-size 64 # 按照自己GPU内存大小大致确定
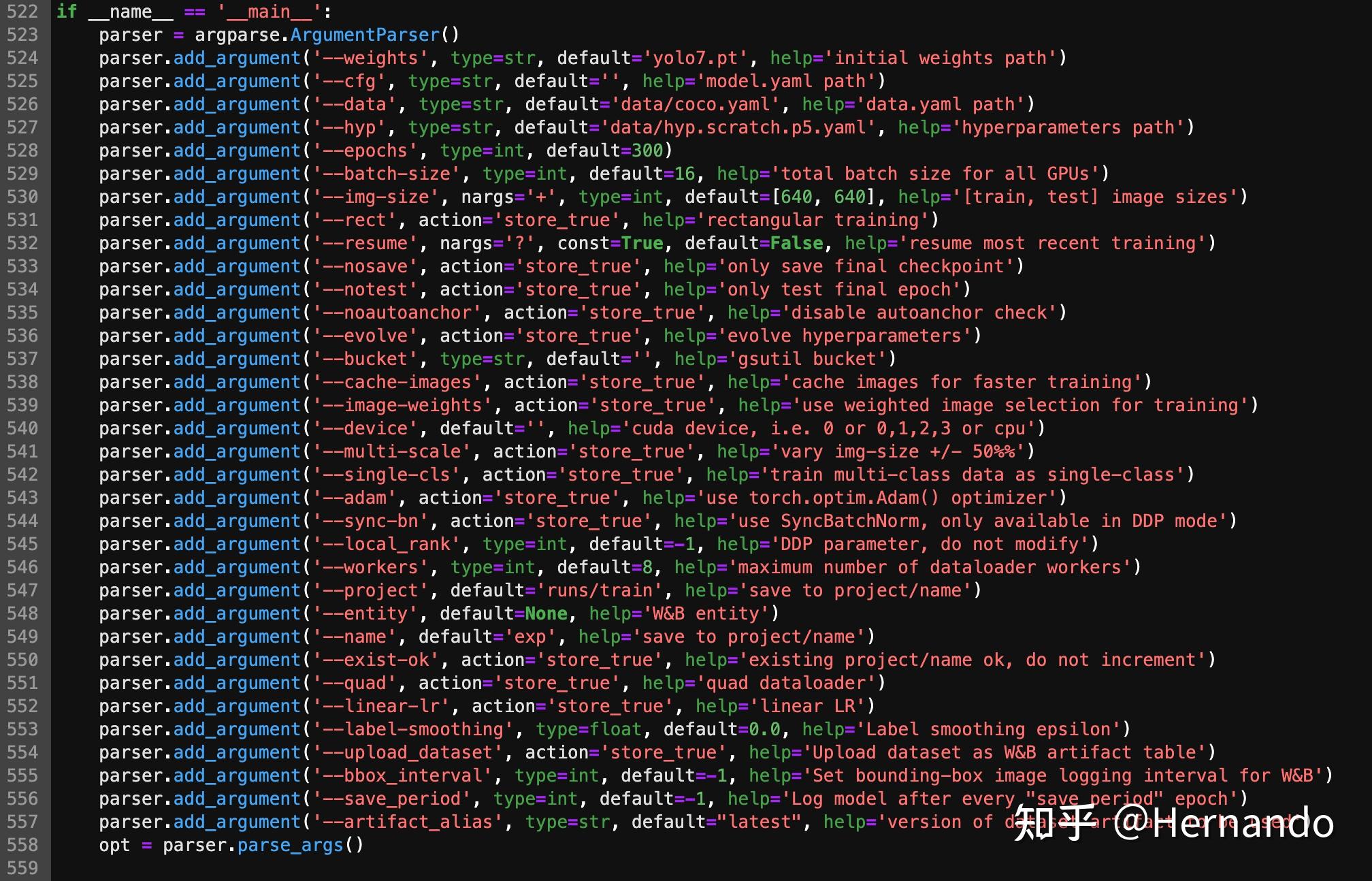
--epoch 10 # 不用多说;我仅展示,因此不训练那么多次了更多的参数可以从train.py文件中找到,如下图
train.py参数
六、训练结果与推理
1. 训练结果
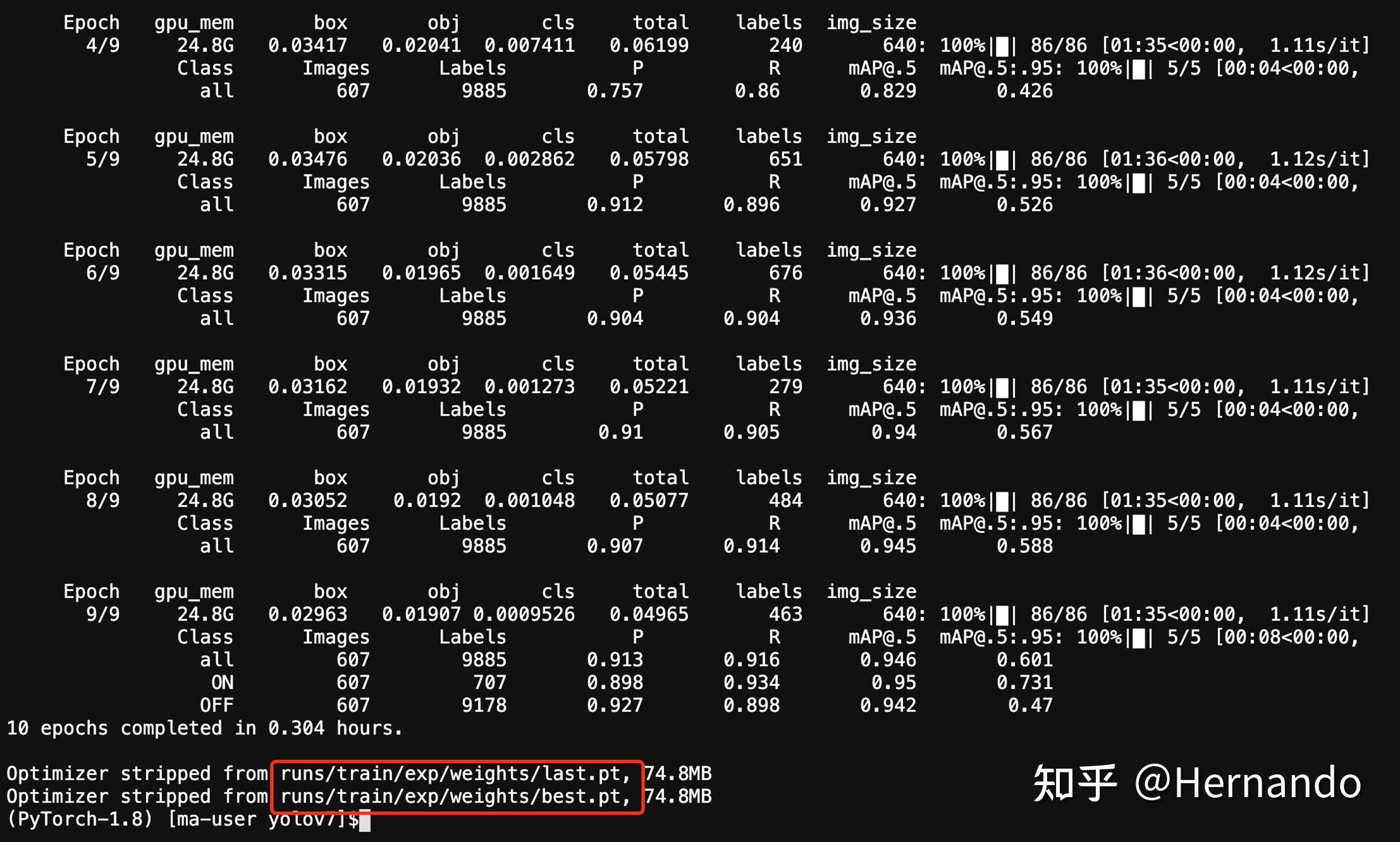
训练结束后,终端会打印出最好的模型和最后一个epoch的模型结果保存在哪里,如下图所示,
训练结束
在/runs/train/exp/下,也存了其他的训练结果文件,比如每个epoch的结果到保存到了.txt文件夹里,如下图所示;有兴趣的可以自行探索。
2. 推理
推理其实就是跟二-4. 测试一下里的差不多,无非就是把相关的权重文件和测试图片换一下即可。
python detect.py --weights runs/train/exp3/weights/best.pt --source datasets/testImages推理的结果如下所示
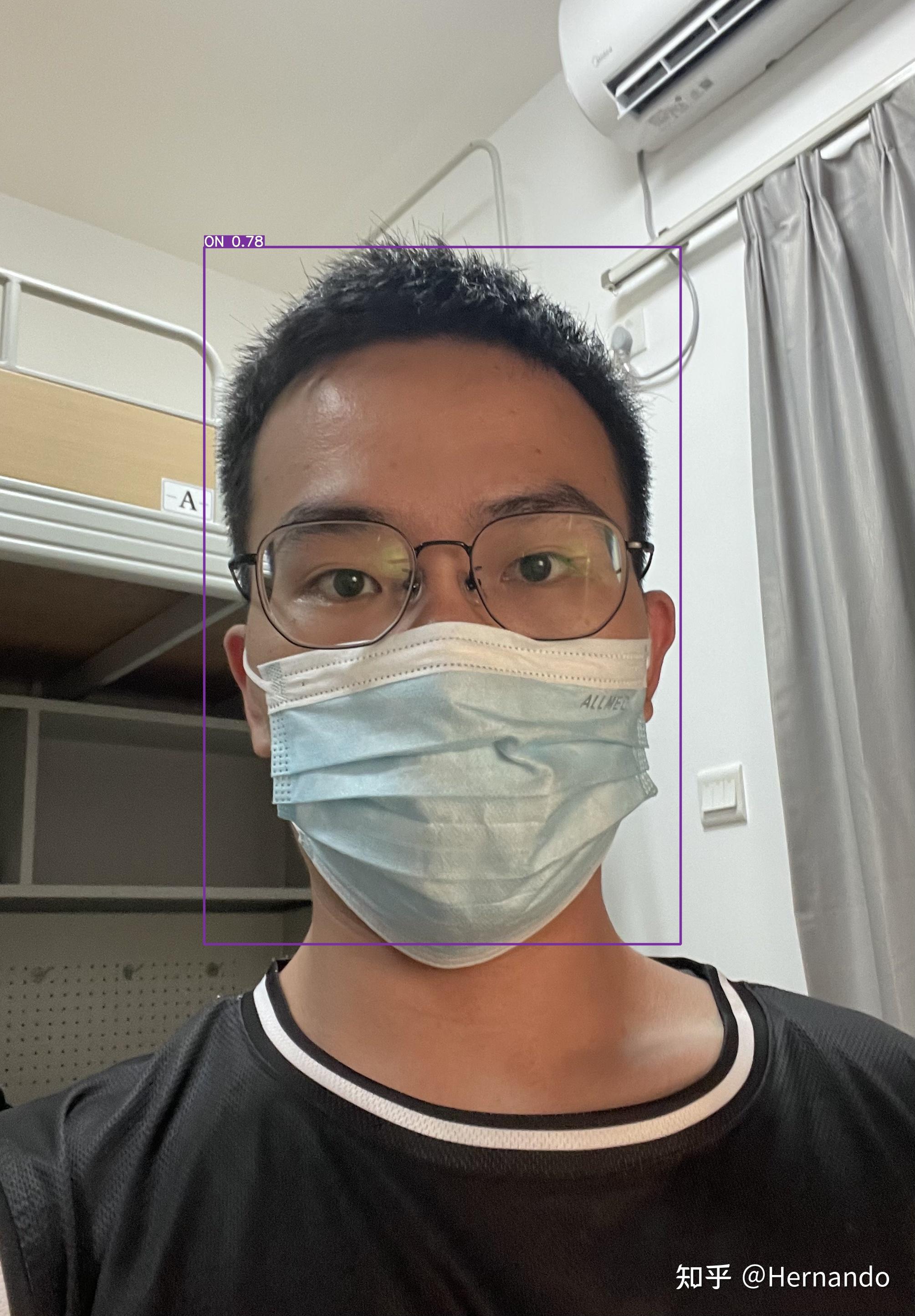
左边两个人正确识别,右边的错误识别,右边属于是训练中模型“没见过”的数据类型,也就是训练数据基本都是整张人脸,但是这里的人只有不到一半的脸,而且角度也不是正面
模型识别为戴头盔,但实际上没戴,因此模型错误识别,这是因为口罩的人脸数据是模型训练过程中“没见过”的,因此会犯错
七、总结
我也是个小白,这篇文章记录了我对yolov7的使用过程,仅作交流分享,如有侵权请联系我。如有问题,欢迎指出。
八、修改与补充
【错误识别问题】2022年9月16日修改
经评论区指出,本文中最后的推理结果把戴着口罩的人识别成了“ON”,也就是戴着头盔。实际上这个人并没有戴着头盔,所以是模型识别错误了,应该识别为“OFF”才对。
原因是这样的,训练数据中所有带着头盔/没戴头盔的图像都没有戴口罩,然后我当时是拍了一张自己的照片做推理,但是想到个人隐私问题,所以就戴上了口罩。我没有考虑到训练数据中没有口罩这个问题,所以当用了一张戴着口罩的人脸去检测时,由于模型在训练的过程中没有见过戴着口罩的数据,因此当推理时见到戴着口罩的人脸时,难免会犯错。
这个问题可以归为“训练数据与测试数据属于不同分布”的问题,在学术界上也有相关的研究。为了严谨,我在原文中贴上一些没有戴口罩的数据识别结果,也就是“与训练数据属于同一个分布”的测试数据的推理结果。
作者:
扎实酱的新柔
时间:
2022-11-25 16:55
写的好详细[赞同]
作者:
她回眸一笑
时间:
2022-11-25 16:56
强
作者:
太阳石
时间:
2022-11-25 16:56
为什么训练的可以,一张图片都推理不出来呢
作者:
微量元素
时间:
2022-11-25 16:57
会不会是推理是参数没写对呢?
作者:
江琴
时间:
2022-11-25 16:57
文内训练的例子是戴和不戴头盔,最后推理的结果图,显示”ON“戴头盔了?推理与事实不符啊?训练无效?
作者:
何锁柱
时间:
2022-11-25 16:58
你好,非常感谢你的指出。戴口罩的这个人脸检测确实是推理与事实不符,但是这个原因不是模型训练无效,而是由于训练过程中模型没有用过戴着口罩的人脸数据去训练是否戴了头盔,因此当推理的时候输入一个模型没见过的数据时,模型就难免会犯错,这是一个比较有价值研究的课题。看得很仔细哦
作者:
高学礼
时间:
2022-11-25 16:59
我也是初学者,还有个疑问,就是定义自己数据集的入口文件,比如:Helmet.yaml,里面定义了训练图集清单(train:xxx\train_list.txt),那么每一张训练图(比如001.jpg),对应的标注数据文件在labels下train\001.txt,这个是哪里定义?还是代码里约定的?在train_list.txt里并没有定义训练图片文件对应的标注数据文件路径啊
作者:
鑫鑫知我心
时间:
2022-11-25 16:59
标签是在数据读取时写在代码里的,具体可以看utils/datasets.py里的img2label_path这个函数
作者:
壹矗垉芐厾
时间:
2022-11-25 16:59
博主,小白初学,制作好的数据集能给我发一份吗万分感谢
作者:
唐小亮
时间:
2022-11-25 17:00
数据集是公开的哈,网上搜一下可以找得到;train_list.txt这些的生成就是简单的python os模块操作,也不难的哈
作者:
天晴了
时间:
2022-11-25 17:00
求问博主,数据集的存放目录格式必须按照文中提到的方式嘛?(读取数据和txt的代码是在哪个部分呀)
作者:
晶品昌田
时间:
2022-11-25 17:00
如果你不想改代码的话,建议数据集还是按照文中的方式存放哈。读取数据和标签的代码在utils/datasets.py的create_dataloader类里面
作者:
地的西瓜
时间:
2022-11-25 17:01
好的,谢谢博主!
作者:
那年风起
时间:
2022-11-25 17:02
大佬!请问一下训练一个模型大概需要多少样本啊
作者:
金字塔
时间:
2022-11-25 17:02
我这个是5000train,600val
作者:
陈强
时间:
2022-11-25 17:03
好的好的!感谢大佬![赞同]
作者:
小菇凉慢慢长大了
时间:
2022-11-25 17:03
我的数据集是先按照test/train/vaild分,再分label和img,也可以用
作者:
马狗猪
时间:
2022-11-25 17:03
按照文件名和路径配对检索的,只要文件名对应就可以了,比如image/train/001.jpg的图片,就会自动找label/train.001.txt作为标签
作者:
服务无止境
时间:
2022-11-25 17:04
推理时输入的图片要先改成正方形的32倍数尺寸的图片,比如640*640或者320*320,然后在参数的--img中设定宽度为修改后的宽度,你看看是不是这个问题
作者:
佳佳牧羊人
时间:
2022-11-25 17:04
你好想问问train_list.txt要怎么生成啊才刚学python[大哭]
欢迎光临 网络问答 (http://corj.cn/)
Powered by Discuz! X3.4