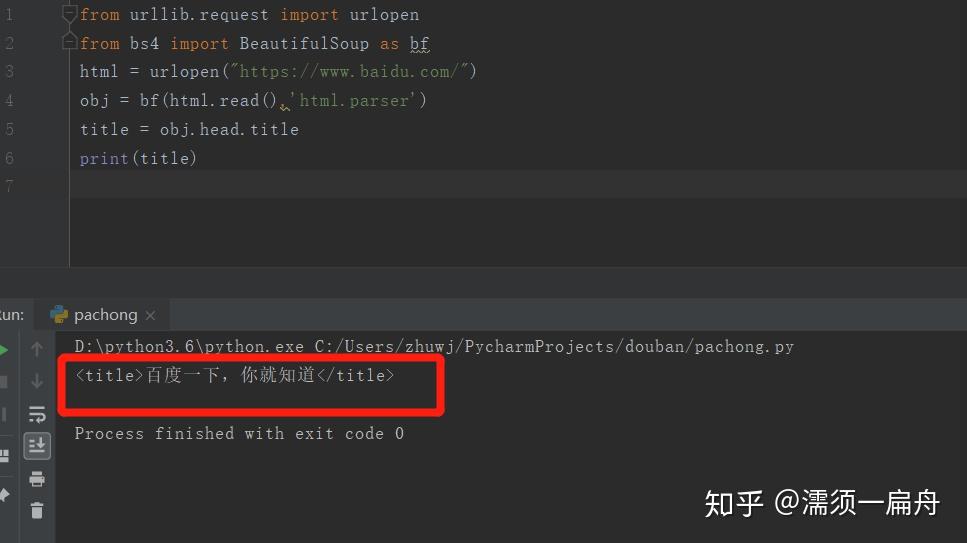
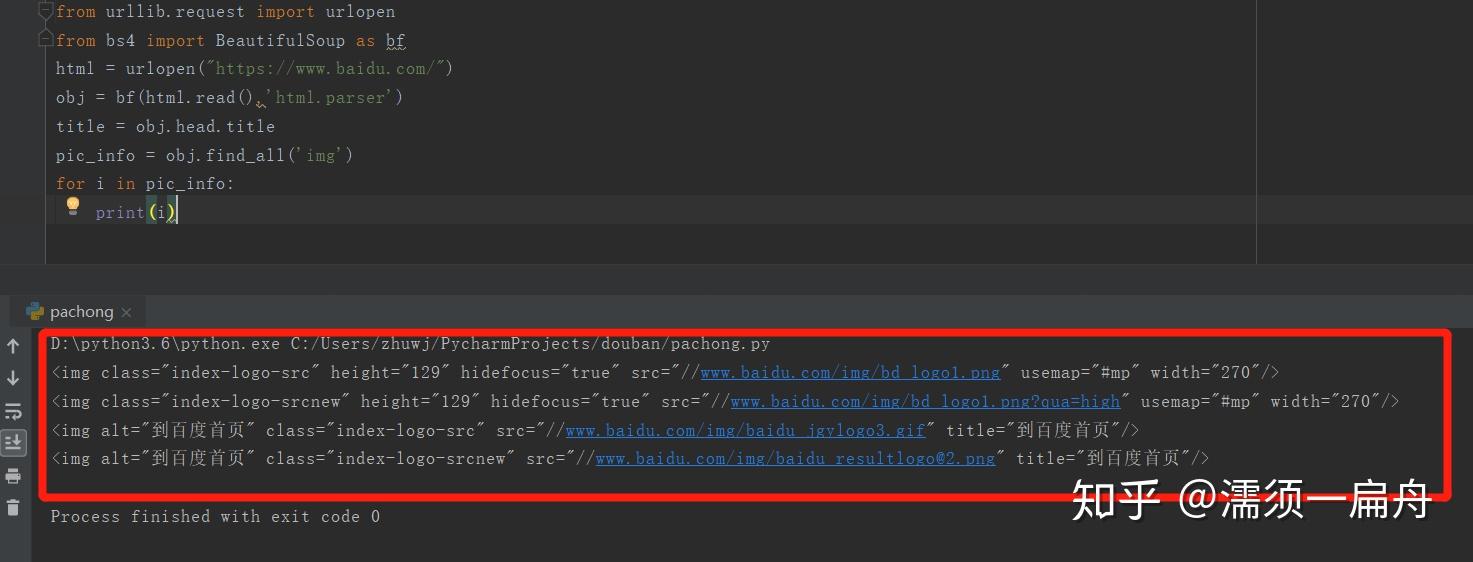
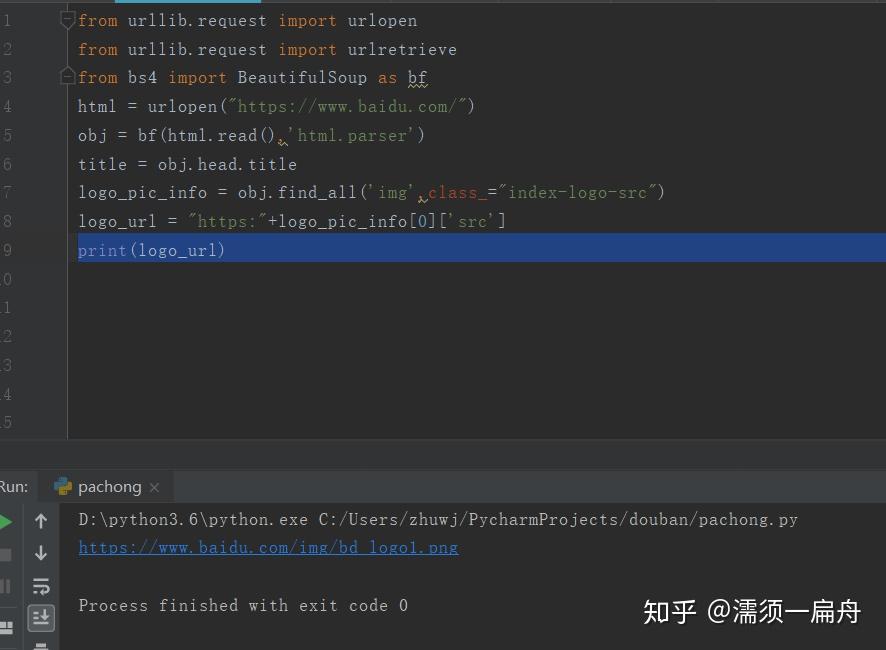
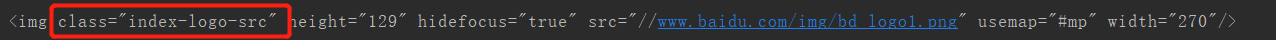3
6
12
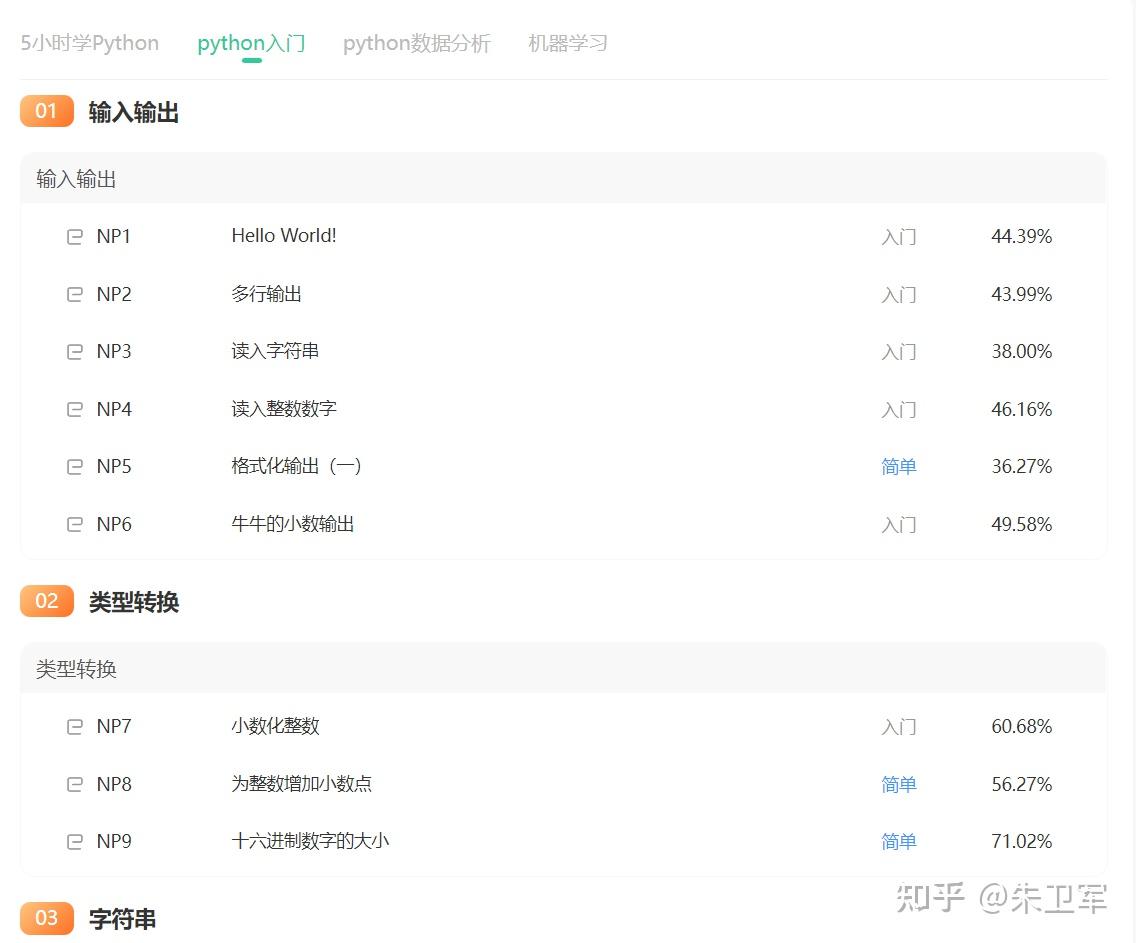
新手上路
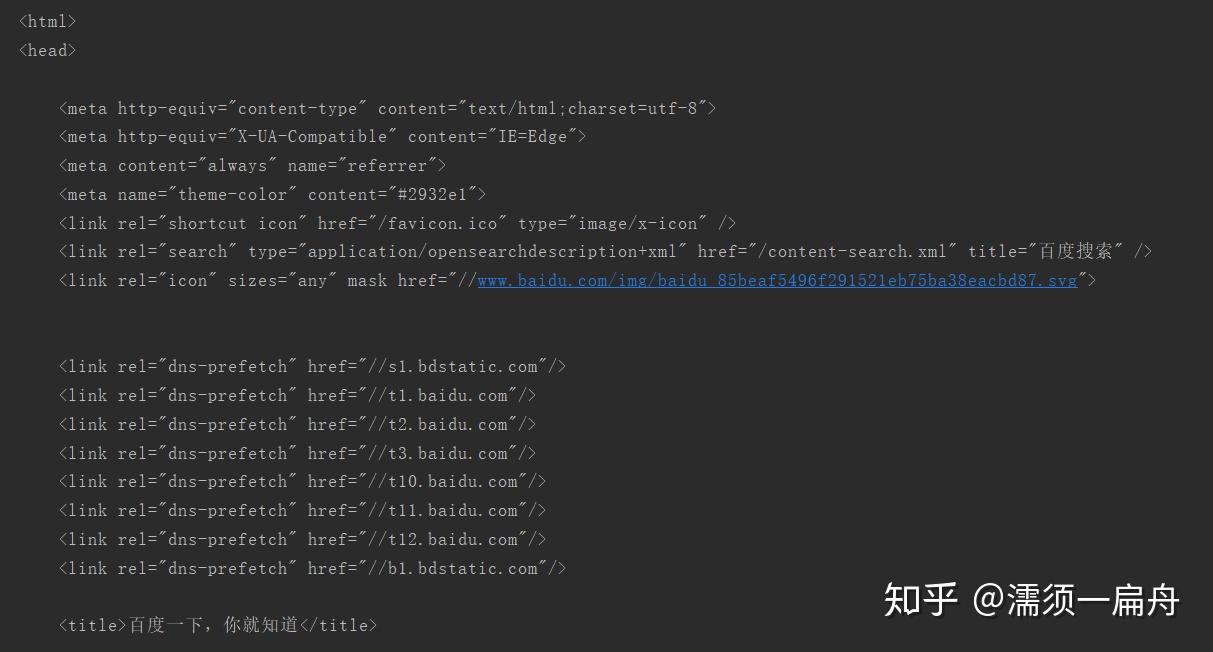
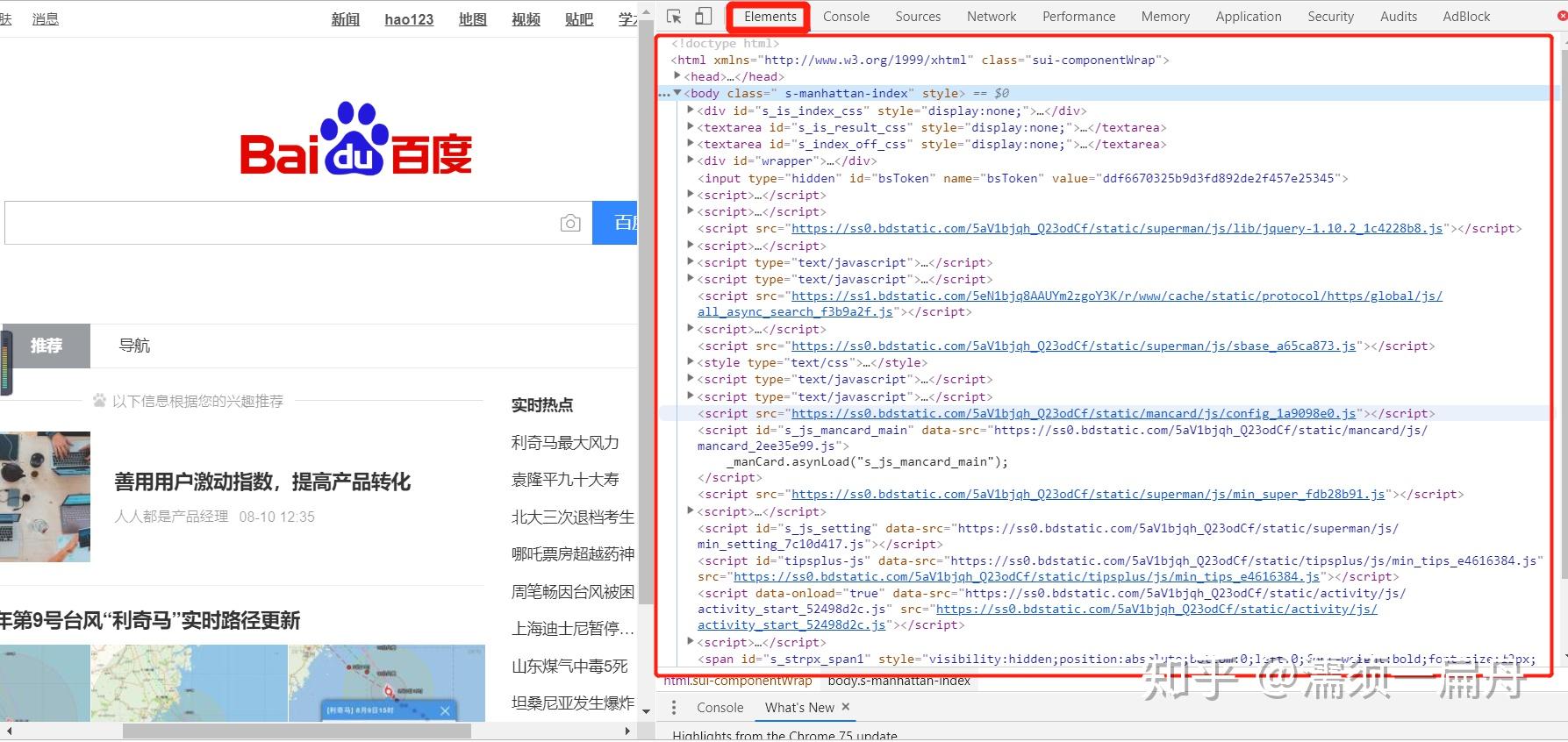
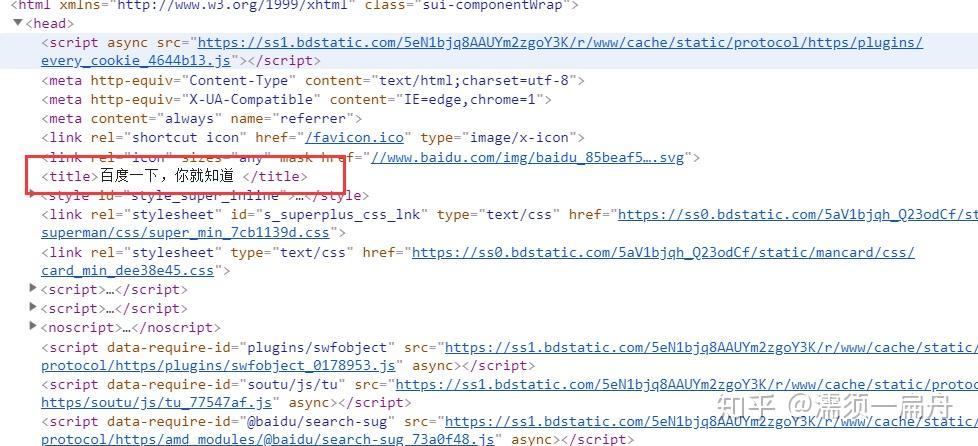
超文本标记语言(英语:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面[3]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
使用道具 举报
2
4
7
1
5
0
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|网络问答
GMT+8, 2025-7-14 10:04 , Processed in 0.063664 second(s), 19 queries .
Powered by Discuz! X3.4
© 2001-2013 Comsenz Inc.
 回复
回复 发帖
发帖


 发表于 2022-11-28 13:36:05
发表于 2022-11-28 13:36:05