|
|
这篇文章主要讨论以下三篇论文:
1:Sketch-Guided Text-to-Image Diffusion Models
2:GLIGEN: Open-Set Grounded Text-to-Image Generation
3:Adding Conditional Control to Text-to-Image Diffusion Models
<hr/>1. 前言
最近笔者在研究院关注的方向主要是如何更好地让图像扩散生成模型更好地受控生成,比如考虑位置(bbox),关键点(key points),速写(sketch)等信息。笔者认为更好地受控生成是扩散模型更好地与设计生产等环节深度结合,使得该项技术真正让用户有付费意愿的关键。其中最近一个月重点针对sketch guidance做了一些探索,有了一些心得,但突然合作的同事发现了一篇工作(上面的第三篇论文ControlNet)不仅在这个方向上做得比较完善了还统一了其他各种模态信息,于是打算简单谈谈在这个方向上踩过的一些坑,解析一下相关工作在收尾时留作记录。
在开始前先感慨下第三篇论文作者Lvmin Zhang这位老哥,21年本科毕业,那他18年大二时便一作发表了ACM Graphics的高引(100+)论文,目前博一便已有12篇工作,真是了不起啊。以下是几张图让大家直观感受下这篇在外网火爆异常杀疯了的技术ControlNet的生成效果。

Credit: https://github.com/lllyasviel/ControlNet/discussions/12#discussioncomment-4948973
<hr/>1:Sketch-Guided Text-to-Image Diffusion Models
这篇是谷歌在2022-12月时发表的一篇论文,使用了classifier guidance的思路,设计了一个称为latent edge predictor的能量模型,能够在Stable Diffusion的noisy latent vector上预测目前该步生成的图片是否有我们sketch对应的边。用当前图像所预测出的边和我们参考的sketch里的边做MSE损失计算,我们可以用该损失的梯度来引导扩散生成的结果,使其生成结果拥有对应的边。
具体关于梯度信息如何引导扩散生成的方法,不了解的小伙伴可以参考我之前的笔记中森:浅谈扩散模型的有分类器引导和无分类器引导。而关于这篇文章里如何低成本地在噪声图像上训练一个有效的能量模型来做梯度引导,读者可以参考论文或者其前序论文<Label efficient semantic segmantation with diffusion models>.
但这篇论文笔者在复现的时候发现最大的问题在于边的生成(梯度引导)是不考虑文本信息且不存在任何交互的。这样独立引导造成的结果就是往往生成的图片带有了相应的边,但和边所对应的语义信息并没有贴合生成的边。举个例子,下图是笔者简单复现的模型对一张黑熊的sketch做引导生成的结果,注意右下角第三张图,边的信息被当作了树枝,但黑熊的生成并没有在那里。论文作者自身也提及了该技术路线存在对于复杂场景(多目标,多主体,或者速写场景边的语义信息模糊,复杂)的生成效果不佳。那么一个很自然的想法就是将sketch features和text features做深度的融合并继续训练,使得生成的可控性提升。
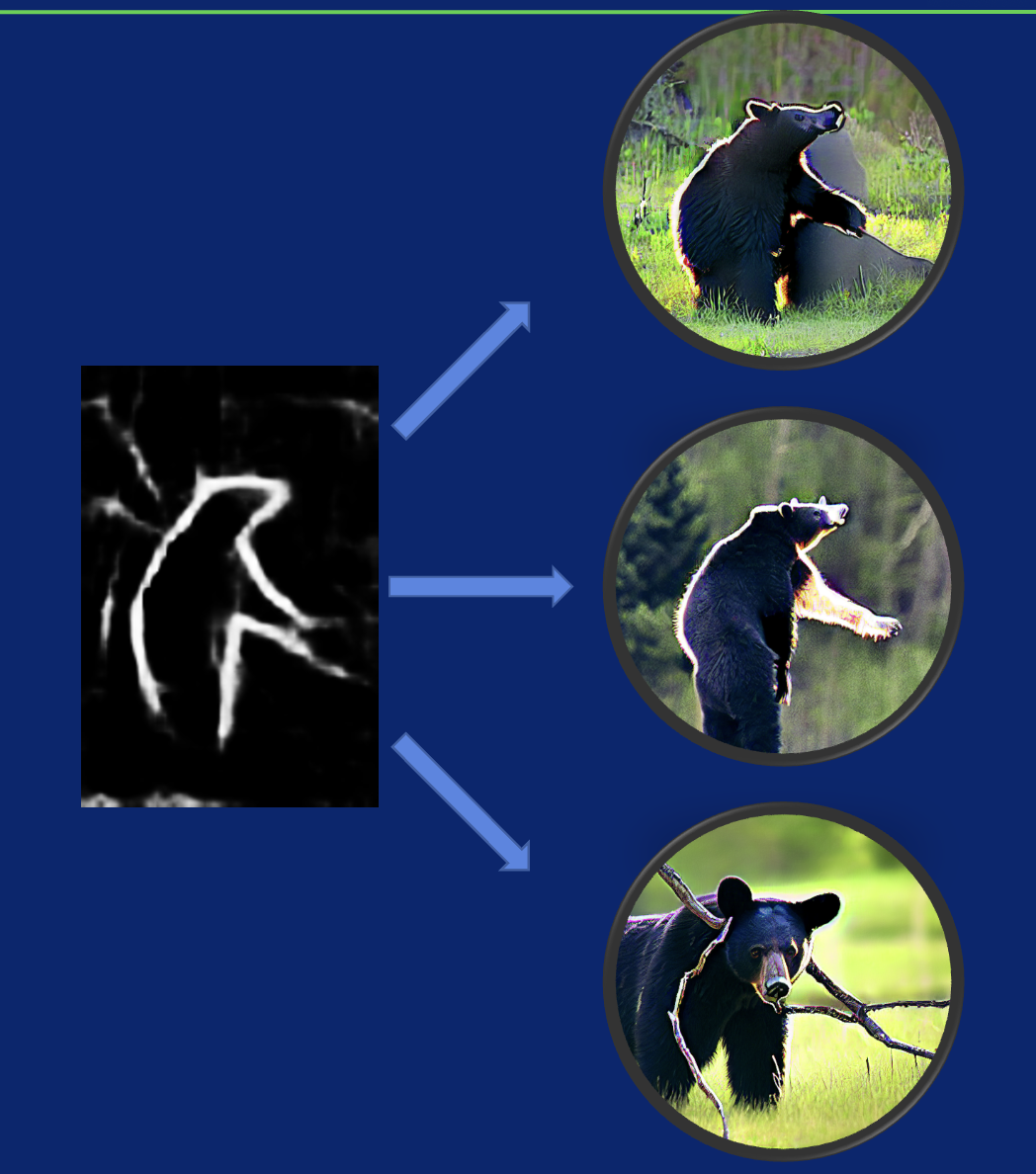
黑熊的速写对应的生成图片
<hr/>2:GLIGEN: Open-Set Grounded Text-to-Image Generation
在开始探讨笔者的思路和第三篇作者Lvmin思路差异前,笔者先简单提及一下在今年一月(23-01)的一篇文章。这篇文章以一个类似于NLP界transformer-adapter的parameter efficient的思路来微调Stable-Diffusion模型(即固定已有模型的参数,只训练在模型里额外添加的组件),并成功使得SD模型可以参考bounding box的位置信息,来对不同实体进行生成。具体架构看下面两张图就十分清晰了,第一张图,我们将bbox的信息和其对应的词的text embedding拼接过一个全联接网络MLP后得到我们的融合表征grounding tokens。这个表征会注入到UNet里self-attn和cross-attn之间,以一个新的架构gated-self-attn的方式添加进网络。其中gated self attn的操作方式图片里也非常清晰了,即以visual hidden states作为Queries, 而visual hidden states 拼接grounding tokens作为Keys and Valus.
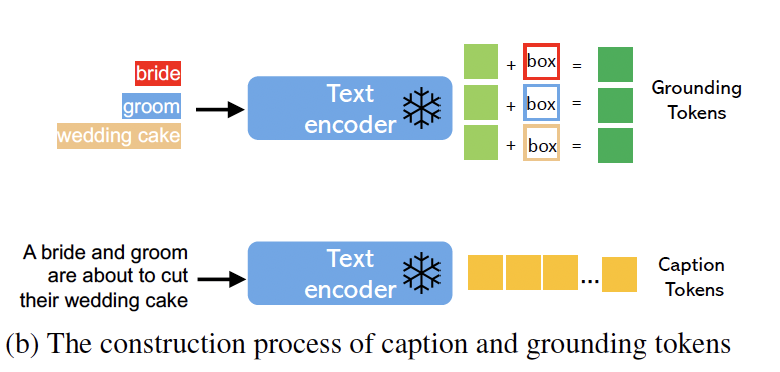
bbox和text的融合示意
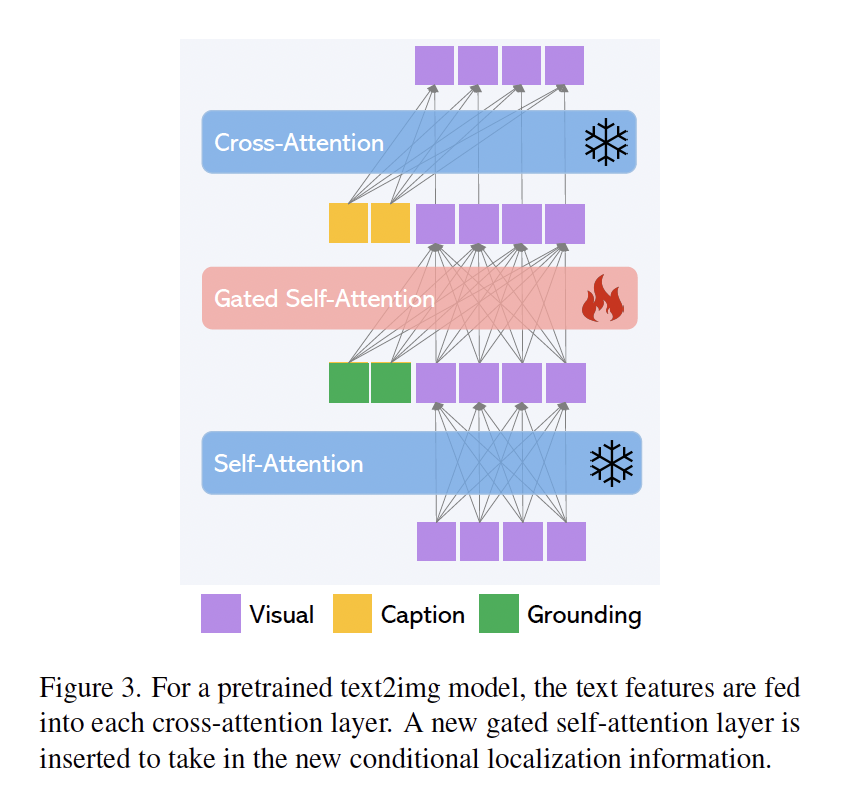
Gated self attention
这篇论文不同于谷歌惯有的不开源不demo,已经在网上放出了demo,效果非常好。笔者认为它对我们的最大启示其实在于它论证了已有的预训练文生图大模型的高度可拓展性,并且在开源模型上添加各种模态控制信息做继续训练高度可行。笔者在做sketch guidance时读到这篇文章也觉得十分振奋,觉得这件事一定能做成,但没想到十来天后,便已经有同行做出了非常漂亮的工作和完善的探索。对于笔者这样的NLP从业人员半桶水来做图像的实验,果然进展还是偏慢,在下一节笔者将讨论笔者所做的尝试和一些心得。反思的同时挖掘作者做法的亮点向其学习。
<hr/>3:Adding Conditional Control to Text-to-Image Diffusion Models
这篇文章笔者认为意义重大,目前作者尚未发布完整版的论文(论文仍有部分章节未完成,但放出了核心方法,实验的模态数据和预训练的权重作为DEMO),但根据论文,这篇文章在一个框架下统一了SD模型添加各种模态做受控生成的方法,包括但不限于Edge Map, Sketch, Depth Info, Segmentation Map, Human Pose, Normal Maps 等。
下面笔者将根据其实验方法分析
1. 如何添加可训练参数
其实关于如何在已有的模型基础上添加可训练参数,达到在新任务上的效果迁移,无论是NLP的transformer时代还是CV里的Diffusion时代都有不少工作。其中在NLP方向上,常见的有添加可训练的 soft prompt tokens(aka prefix tuning), adapters, 平行模型等。关于在Diffusion Models上添加新组件的有把Video的3D用2D文生图参数启动但是额外添加一个卷积维度,有需要添加输入端额外维度的依赖在输入端添加新通道,有类似于GLIGEN的在self/cross attention间添加注意力模块的融合方式,当然也有额外添加一个encoder添加模型之类的工作。
但是ControlNet的做法不同,具体来说,对于预训练好的模型(比如作者使用SD1.5-UNet里Encoder和MidLayer的ResNet和Transformer层)里的一层结构, 作者固定了其参数,并将该层的输入额外添加了一个全联接映射后的条件c,输入到一个和该层结构一致的复制网络里,再映射一次后重新添加回原结构里的输出。按照作者的解释来看,这样做的好处有两个:一个是最大程度的保留原模型的生成能力,另一个是新添加的组件将以0值初始化所以在优化的初始阶段该模型的输出与原模型等价。
作者的安排十分有意思。笔者在做相关实验时会联想到学术界已经形成的一些共识来设计实验:比如由去年八月份论文prompt to prompt提出后,文生图里图片布局几何关系很大程度上由cross-attn时文本对不同位置的像素点的激活程度所决定。所以笔者初始时会思考是否可以直接将text embedding添加融合模块与sketch info(或其余模态的信息)交互,微调整个模型使其学会兼顾新的模态信息。笔者也会思考是否直接像GLIGEN的方式直接在attn层附近添加融合模块会取得好的效果。但论文作者没有如此安排。论文作者的思路更加类似于《Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation》这篇论文的思路。即对于一张模型生成的图片,其UNet的decoder一定已经包含了其生成的一些空间信息,语义信息等。直接抽取decoder相关的特征,添加到当前的生成能够影响当前生成的布局语义等。这是笔者觉得非常有意思的一点。
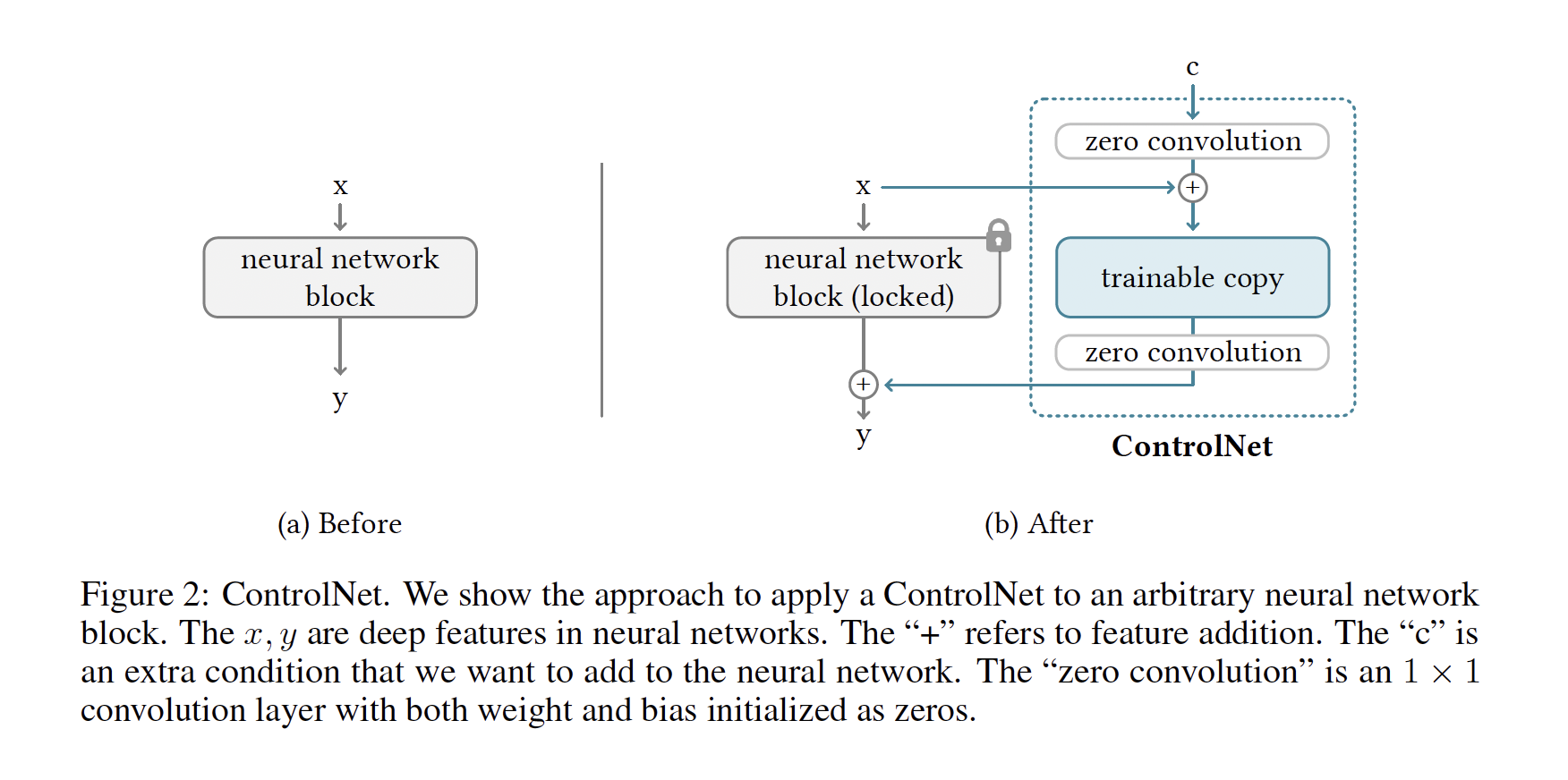
ControlNet的核心架构区别
2. 如何融合模态信息
上面笔者简单提及了一下像笔者这样的路人研究者会如何朴素地思考添加额外引导信息的一些可能方式,但是笔者尚未提及这些额外的引导信息是如何与现有模块融合的。融合模块该如何设计,引导信息如何添加是这篇论文成败的关键。
作者在这方面所使用的方法也十分特别。如果笔者根据代码及论文总结得无误的话,作者是用统一架构处理所有不同输入来指导生成的。如笔者这样的路人研究者会思考不同的输入信息其本质差异较大,或许需要不同的处理方式。比如sketch VS edge 实际差异很大。对于一栋建筑所提取的canny edge必然是忠实于图像里建筑本身的几何关系,空间位置等。但sketch的抽象属性会出现形状不符合,空间位置不对齐,相对比例不准确等一系列问题。所以笔者甚至考虑针对edge 和sketch要引入不同的训练目标损失,以类似风格迁移评估整体相似程度的方式来处理sketch模态信息的输入。但事实是,论文作者以一个架构一个方法便整合了所有不同模态的输入处理,这是方法论层次上的碾压。如同NLP里有专注做命名实体识别,关系抽取,指代消融,概括段落等任务,但ChatGPT出来以后这些任务全部都被整合到一个模型一个框架里一样。
那作者提出的架构为何可以做到这一点, 笔者抛砖引玉提出几个可能的关键因素:
1:输入数据的量级。作者所针对的每一个模态,都可以通过已有模型的基础上快速获得大量数据(比如canny filter对edge的提取,midas对深度图的提取等)。类似于InstructPix2Pix这篇工作,针对当前任务造出一个百万级别大小的训练数据,可能是微调模型使其学到隐式关系的关键。
2:作者提出的架构和对额外模态的输入形式使得一个通用架构成为可能。在上面介绍结构时,笔者提到作者是针对UNet的前半部分里的每一层做额外信息添加和复制训练的。其中当然就包括了Resnet的卷积层。即无论什么模态的信息,作者的架构都可以把它作为图像通过UNet的encoder对其进行多尺度的信息特征的提取。大量参数(对Encoder+MidLayer的复制)加上大量训练数据加上适配的网络架构可能是其成功的关键。
3: 对信息的添加及添加位置的选定。前面两个原因笔者认为可能是较为直接的关键因素。但第三个原因笔者不确定其重要程度,或许可以留待作者的消融实验看看是否有相关讨论。如果直观上来理解,在UNet的encoder阶段添加模态信息引导使得Decoder生成时考虑到相关添加信息当然符合直觉。但为何作者没有选定(只)在Transformer层这样的模态信息制导生成的关键位置添加模块,而是一视同仁且是在每一层的结尾做信息融合。笔者暂时没有一个很好的回答。
3.如何drop text info来增加对condition info的依赖
这一点是笔者在做语言模型,VAE时观察到的一些现象。举个例子,在这几年的语言大模型训练时,作者通常会训练一系列语言任务来“挑战“大模型,使其能够学到重要的特征。这是个很基础的思想在对比学习在各种神经网络训练里都会出现。对于已经预训练好的stable diffusion模型来说,其本身已经可以通过文本的制导,生成高精度的准确图像并且训练时拟合的损失已经很低了。换句话说,额外的模态信息在功能上是和文本有重合的,如何让模型不对输入的额外模态信息完全忽略导致训练崩塌或许是个作者没有提及但实验时会碰到的情况。笔者在训练sketch guidance时便发现了这个情况。笔者初期采用的方式是对text info进行dropout, 但作者采用的方式更为直接,是以类似Classifier-free-guidance的方式直接对整个text info进行忽略,使得模型不得不从模态信息里提取相关特征以辅助训练。
<hr/>末尾
写在最后。笔者在研究院里是NLP中心下的一个算法工程师。笔者所在的NLP中心关注的是AIGC方向的生成,比如扩散模型比如最近大火的ChatGPT。笔者马上要被抽调去做回老本行NLP的ChatGPT相关内容了,后续可能更新扩散模型方向的内容会开始减少,但笔者将持续关注多模态生成尤其是类似于BLIP-V2这样融合语言与图像方向的工作。欢迎做相关方向研究的同行私信一起讨论。 |
|
 回复
回复 发帖
发帖


 发表于 2023-5-1 16:27:50
发表于 2023-5-1 16:27:50